
Fun with mismatched encodings
Mojibake is the garbled text that result from character-encoding errors.
If you’ve seen text that looks like this — and I’m sure you have — then you’ve seen mojibake.
(You should be seeing something like this:
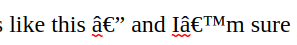
If you see something else, this post may be a little confusing and you need a new web browser.)
Computers represent text as a sequence of bytes, and “text encodings” are dictionaries that turn characters (i.e. symbols: letters, punctuation, etc.) into bytes and vice-versa.
The garbled text above is a pretty common species of mojibake. It’s what happens when em-dashes and curly apostrophes are encoded as bytes with UTF-8 (the now-nearly-universal text encoding) and decoded back to characters with Windows-1252 (an obsolete encoding that is still pretty widespread).
Windows-1252 is pretty straightforward: each character gets one byte, and there are only 256 characters so this works out.
UTF-8 is one of several character encodings based on Unicode, which (for our purposes) is a massive numbered list of over 100,000 characters. Unicode includes nearly every language in the world and a bunch of other nonsense like emojis.
UTF-8 turns each character into a sequence of up to four bytes based on its Unicode “codepoint” (position in the list). Codepoints are bigger than bytes, so you still need this translation step.
(I’m simplifying a little here, and you should be grateful for that.)
Specifically, an em-dash gets mangled like this:
- EM DASH (—) is Unicode character #8,212, usually written (in hex) as U+2014.
- UTF-8 encodes the number 8,212, which is too big to fit in a single byte, as the sequence of bytes 0xE2, 0x80, 0x94
- Windows-1252 looks at each byte in turn and decodes them directly as the characters â, €, ” respectively.
- Finally, your computer looks up the characters â, €, ” in some font file and draws the specific glyph for each of those characters in that font. (A “glyph” is the actual picture on your screen; a “character” is the abstract concept of the euro symbol or whatever.)
(I made this happen deliberately with python: '\u2014'.encode('utf8').decode('1252').)
This sometimes happens to the same text multiple times, and special characters turn into exponentially-growing strings of nonsense that overwhelm the text:
An astrological mystery
I saw this today on a used-book website:

Astrological symbols??
My first thought was that this was something like the above, but with a different output text encoding in place of Windows-1252. But this isn’t really plausible; since UTF-8 encodes dashes and apostrophes as three bytes apiece, the other encoding would have to have a multi-byte sequence for ☋, the “descending node” astrological symbol. The main problems with this are that UTF-8 is the only multi-byte encoding in widespread use, and that (AFAIK) Unicode is the only character set in widespread use that includes ☋.
Maybe it’s reversed? Text goes into a legacy encoding and comes out of UTF-8 looking like ☋? This has the same problem: UTF-8 encodes ☋ as 0xE2, 0x98, 0x8B, another three-byte sequence. No other encoding is going to use three bytes for an em dash.
A rogue font
But then I remembered something wacky about my computer.
A bunch of Unicode characters are “control codes” rather than text characters in the usual sense, like U+000A NEW LINE (inserts a line break) and U+200F RIGHT-TO-LEFT MARK (makes subsequent text appear right-to-left, like Hebrew or Arabic). The first 32 characters from U+0000 to U+001F are a set of control codes inherited from ASCII, which was designed for teletype machines. They’re mostly garbage like “END OF TRANSMISSION BLOCK” and “DEVICE CONTROL FOUR” that make no sense in a digital context. (My favorite is U+0007 “BELL”, which originally rang a physical bell on the teletype to alert the operator. This one still sometimes works! Some programs will make a “ding” sound when they render text containing the BELL character.)
Typically, these legacy codes render as an empty box (meaning “this font doesn’t have a glyph for that character”), or a replacement glyph like ␔ (should look like “DC4” for “DEVICE CONTROL FOUR”), or (incorrectly) the “encoding error” glyph � (question mark in a diamond), or just aren’t rendered at all.
The way this happens is that your computer asks a bunch of different fonts in turn to render the character. Each font either says “sure, here’s a glyph” or “nope, try someone else”. Usually, a font eventually says “sure, here’s a glyph: it’s the ‘I don’t know that symbol’ glyph”, and a box or something appears on your screen.
On my computer, in the depths of the font collection, the TeX package wasysym has stored a font which uses the ASCII control codes as spare room for extra random symbols, including things like astrological symbols, music notes, and APL symbols (don’t ask).
This is sort of like a character encoding, except that it’s happening in the wrong place: someone else has already decided that some string of bytes means DEVICE CONTROL FOUR, and the font is overriding that decision by lying and pretending that a “DEVICE CONTROL FOUR character” looks like ☋.
So when my browser tries to render the character U+0014 — regardless of the string of bytes and text encoding it used to get that character — it asks a bunch of fonts, and they each go “what? that’s DEVICE CONTROL FOUR, I can’t draw that garbage”, and then the wasysym font says “sure, I know what that looks like!” and draws… the Descending Lunar Node symbol.
That’s not how bytes work
But that’s only half the story here. Why does this plot summary have a DEVICE CONTROL FOUR character in it? Or END OF MEDIUM, the thing that ends up looking like the Venus symbol ♀︎?
At this point, I was pretty sure I’d found the actual text-encoding error. You see, UTF-8 encodes the first 128 Unicode characters U+0000 through U+007F as the single bytes 0x00 through 0x7F. (This is for backwards-compatibility with ASCII.) Surely, some ancient encoding was putting em-dashes and apostrophes down in the low bytes 0x14 and 0x19, and these bytes were getting decoded as control codes by UTF-8, and then incorrectly rendered as astrological symbols by wasysym.
This also turned out to be wrong. Sure, there are text encodings that put symbols in the low bytes — code page 437 uses 0x14 and 0x19 for the paragraph symbol ¶ and down arrow ↓ — but none of them put the em-dash or curly apostrophe there.
….On the other hand, em dash and curly apostrophe are unicode characters U+2014 and U+2019. That seemed like a clue.
One possibility is that the website isn’t really using a text encoding at all, but instead using a hand-coded approach of taking the Unicode codepoint modulo 256 and writing down the corresponding byte. This is total nonsense for most Unicode characters, but it does work for the ASCII characters (including basic Latin letters, numbers, and punctuation) because their codepoints are below 256 and UTF-8 maps them to the corresponding byte anyway.
If you use Windows-1252 to decode those bytes, it kind of also works for an additional 96 characters, because the Unicode codepoints (but not the UTF-8 bytes!) for those are assigned in an almost identical way to the Windows-1252 bytes. So this is something that I can imagine someone misguidedly doing. The only problem is that any codepoint higher than U+00FF, including em dash and curly apostrophe, is going to get mapped to a fairly arbitrary character in the 0000-00FF range.
A variation on this (thanks to a friend for pointing this out): The character encoding UTF-16 is another Unicode encoding like UTF-8, but it encodes characters as 16-bit words instead of bytes. To get a sequence of bytes, these words just get chopped in half. And in UTF-16, most of the Unicode codepoints between U+0000 and U+FFFF are mapped directly to words between 0x0000 and 0xFFFF. (Higher codepoints get multiple words, like UTF-8’s multi-byte sequences.) In particular, U+2014 is encoded as 0x2014, which then becomes either 0x20 0x14 or 0x14 0x20 (depending on which variant of UTF-16 it is).
So maybe someone noticed that their normal everyday ASCII text, like CAPITAL LETTER A (U+0041), was getting encoded as as 0x00 0x41. Or maybe they were trying to encode with UTF-16 and decode with UTF-8 (or ASCII or Windows-1252), and they kept ending up with null characters (U+0000 NULL) in between all their letters and numbers. Either way, they decided to just delete every other byte, and this sort of worked — until they needed to encode something that wasn’t an ASCII character.
At any rate, it turns out there’s no mere character encoding mismatch here! On both the encoded (byte) and decoded (glyph) side of things, things are being nefariously meddled with.
What’s happening is something like:
- Em dash is encoded in UTF-16 (or copied directly from its codepoint) as 0x20 0x14
- Every other byte is deleted (meddling #1)
- 0x14 is decoded in UTF-8 (or something) as DEVICE CONTROL FOUR, an unprintable teletype control code
- A rogue font insists that it knows how to draw that (meddling #2)
- It draws DESCENDING LUNAR NODE instead
Future work
I’m sorely tempted to find a book whose blurb contains a non-ASCII character that’s in the same place in Windows-1252 and Unicode, like U+00E1 (á), on this website. That would disambiguate some of these options: 0xE1 decodes as á under Windows-1252, but not under UTF-8 which parses it as garbage.
(Preemptive edit: I did find some book blurbs like that, and they rendered fine, but I’m not sure whether to trust this data. Maybe the buggy description was mangled at some earlier stage, and copied to this website with the control codes already in place…)
Better yet, an emoji character or an obscure Chinese character — which both require multiple UTF-16 words — would disambiguate between the UTF-16 and “codepoint mod 256” hypotheses.

